Overall 10/10. A short concise book with a number of good ideas that anyone working in a large/medium or perhaps even a small company would benefit from. So good, that I re-read parts of it twice already.

Book Notes:
Andy uses the analogy of making a breakfast to show how process->assemble->test is a common workflow at any scale. For me many of his points in manufacturing paralleled topics from lean/agile software development.
Inspection Methods:
– In-process inspection e.g. theremometer for boiling eggs
– Receiving inspection e.g. Inspecting eggs on delivery, parallel in software: validating user requirements
Each step takes time/effort and ads value, best to eliminate waste at the earliest stage.
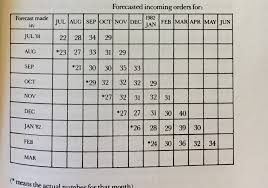
Picking Good Indicators: Indicators chosen dictate our direction.
– Pairing Indicators – prevent overfitting e.g. From scrum points done with busines value delived. Quantitive and qualitive often pair well.
– black-box = Just measure in/output
– Cut a hole in the box to get leading indicators. Can look at a linear indicator (graph) or a stagger chart to ensure going at correct speed or to allow estimation.

Controlling Future Output -Goal should be to keep inventory at earliest, lowest cost stage.
1. Build to order
2. Build to forecast
Assuring Quality
– Act as a gate – Inspect everything, push back rejects
– Monitoring Step – Inspect some, stop line on problems
Variable Inspection Best – Too regular = expected, too few = gaps, no problems = inspect less, problems = inspect more, dive into one at random.
I thought some of this may be very applicable to software, consider for example Pull Reviews or User Stories or Releases, how often should senior developers ensure requirements have been gathered adequately, that jiras are well written, or inspect juniors code. Though on that last point of managing people Andy very much suggests focussing on TRM – Task Relevant Maturity,
Misc
Nudges – Most of a managers day is gathering information. After that there are a few direct decisions but often it will be a case of nudges. Gently influencing items in the direction you think best. Note combined with Andys other point that (Managers Output) = (Output of his Org) + (Output of neighbouring Orgs) this nudging of nearby teams can be very powerful for the company overall.
Hybrid Organisations
Organisations come in two extreme forms:
Mission Oriented = Small hedge fund where everyones goal is to make money
Functional Oriented = IT Support within a bank, whos goal is to deliver IT assistance.
The hybrid organisational form is inevitable. The company I think of is when considering these concepts is McDonalds. McDonalds will have a global marketing department ensuring consistency of branding but it will also have regional departments deciding which offers to run. Similarly some resources such as packaging will be produced in a shared department while regional speciailities can be ran at a much lower level. There will always be a conflict between the goals of these different groups but similar to democracy being the least worst form of government, hybrid organisations appear to be the least-worst method of organisation.
A related concept is Dual Reporting – Individuals can be individual contributors within one team e.g. coders but at other times contribute firm-wide as part of standards committees etc. This allows using their skill sets to the fullest.
…One-to-ones, meetings and a number of other topics were also covered in the book.
Key Takeaways for Me
I really like the idea of paired indicators. Once you’ve heard the concept it’s easy to see other teams doing it wrong and only looking at one indicator. e.g. Within large finance firms there are change management or support teams whose job is to ensure stability of all systems, the metric they will almost always look at is outages and their severity. You will typically see a line or bar chart over time reported or perhaps a breakdown by team. A high number of outsages by a particular team can result in their releases being frozen. I would suggest this metric should be weighted against business value delivered. Does it matter if a system crashes badly once a week if it prints money the rest of the time? Compared to say an accounting system that never fails but delivers little additional value.
What work should a manager do? The manager is responsible for overall team delivery. Therefore a manager should work on the highest leverage item. I think Andy is right that training is an extremely high leverage activity given the return over time. Training someone now, will lead to higher quality output later. Higher quality out = less quality checks aer required and staff are happier. The importance of training does however make you wonder about the impact of the rapidly increasing employee turnover in some countries and the increased reluctance of firms to invest in training.
TRM – Task Relevant Maturity. Either someone refuses to work or can’t do the work. Their ability to do the work will depend on their Task Relevant Maturity. When considering how to assign and monitor tasks, the key metric to keep in mind is TRM.
Summary
As I said at the start, a really good book. Some of his ideas I will have to take time to digest and consider how it would change my approach to certain work. Andy even included a todo list for once you’ve finished the book that I have partly completed. The parts of the book that I was more sceptical of, I plan to force myself to consider more fully. Given how knowledgable and accurate Andy was in some areas I have experience of, I shouldn’t dismiss him in the areas that seem to me more dubious.




 n support team has typically been tasked with “zero outages” whilst the developers are incentivised to develop and release as quickly as possible, with some front-office “quant-devs” not being held accountable for stability at all. With the handover method looking like throwing it over a wall:
n support team has typically been tasked with “zero outages” whilst the developers are incentivised to develop and release as quickly as possible, with some front-office “quant-devs” not being held accountable for stability at all. With the handover method looking like throwing it over a wall: ibilities back and forth from DEV to SRE owned. Importantly the target e.g. between 99.8% and 99.9% uptime should have an upper and lower bound, it should NOT be an absolute. If you go above it, developers should be taking more risks, below, developers should work on stability.
ibilities back and forth from DEV to SRE owned. Importantly the target e.g. between 99.8% and 99.9% uptime should have an upper and lower bound, it should NOT be an absolute. If you go above it, developers should be taking more risks, below, developers should work on stability.